
ElasticSearch概念与安装

ElasticSearch概念与安装
SerMsElasticsearch 是什么

The Elastic Stack, 包括 Elasticsearch、Kibana、Beats 和 Logstash(也称为 ELK Stack)。能够安全可靠地获取任何来源、任何格式的数据,然后实时地对数据进行搜索、分析和可视化。Elaticsearch,简称为 ES,ES 是一个开源的高扩展的分布式全文搜索引擎,是整个 Elastic Stack 技术栈的核心。它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理 PB 级别的数据。
PS:elasticsearch是一款非常强大的开源搜索引擎,具备非常多强大功能,可以帮助我们从海量数据中快速找到需要的内容
全文搜索引擎
Google,百度类的网站搜索,它们都是根据网页中的关键字生成索引,我们在搜索的时候输入关键字,它们会将该关键字即索引匹配到的所有网页返回;还有常见的项目中应用日志的搜索等等。对于这些非结构化的数据文本,关系型数据库搜索不是能很好的支持。
一般传统数据库,全文检索都实现的很鸡肋,因为一般也没人用数据库存文本字段。进行全文检索需要扫描整个表,如果数据量大的话即使对 SQL 的语法优化,也收效甚微。建立了索引,但是维护起来也很麻烦,对于 insert 和 update 操作都会重新构建索引。
基于以上原因可以分析得出,在一些生产环境中,使用常规的搜索方式,性能是非常差的:
- 搜索的数据对象是大量的非结构化的文本数据。
- 文件记录量达到数十万或数百万个甚至更多。
- 支持大量基于交互式文本的查询。
- 需求非常灵活的全文搜索查询。
- 对高度相关的搜索结果的有特殊需求,但是没有可用的关系数据库可以满足。
- 对不同记录类型、非文本数据操作或安全事务处理的需求相对较少的情况。为了解决结构化数据搜索和非结构化数据搜索性能问题,我们就需要专业,健壮,强大的全文搜索引擎。
这里说到的全文搜索引擎指的是目前广泛应用的主流搜索引擎。它的工作原理是计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。
elasticsearch和lucene
elasticsearch底层是基于lucene来实现的。
Lucene是一个Java语言的搜索引擎类库,是Apache公司的顶级项目,由DougCutting于1999年研发。官网地址:https://lucene.apache.org/ 。

elasticsearch的发展历史:
- 2004年Shay Banon基于Lucene开发了Compass
- 2010年Shay Banon 重写了Compass,取名为Elasticsearch。

Elasticsearch And Solr
Lucene 是 Apache 软件基金会 Jakarta 项目组的一个子项目,提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。在 Java 开发环境里 Lucene 是一个成熟的免费开源工具。就其本身而言,Lucene 是当前以及最近几年最受欢迎的免费 Java 信息检索程序库。但 Lucene 只是一个提供全文搜索功能类库的核心工具包,而真正使用它还需要一个完善的服务框架搭建起来进行应用。
目前市面上流行的搜索引擎软件,主流的就两款:Elasticsearch 和 Solr,这两款都是基于 Lucene 搭建的,可以独立部署启动的搜索引擎服务软件。由于内核相同,所以两者除了服务器安装、部署、管理、集群以外,对于数据的操作 修改、添加、保存、查询等等都十分类似。
在使用过程中,一般都会将 Elasticsearch 和 Solr 这两个软件对比,然后进行选型。这两个搜索引擎都是流行的,先进的的开源搜索引擎。它们都是围绕核心底层搜索库 - Lucene构建的 - 但它们又是不同的。像所有东西一样,每个都有其优点和缺点:
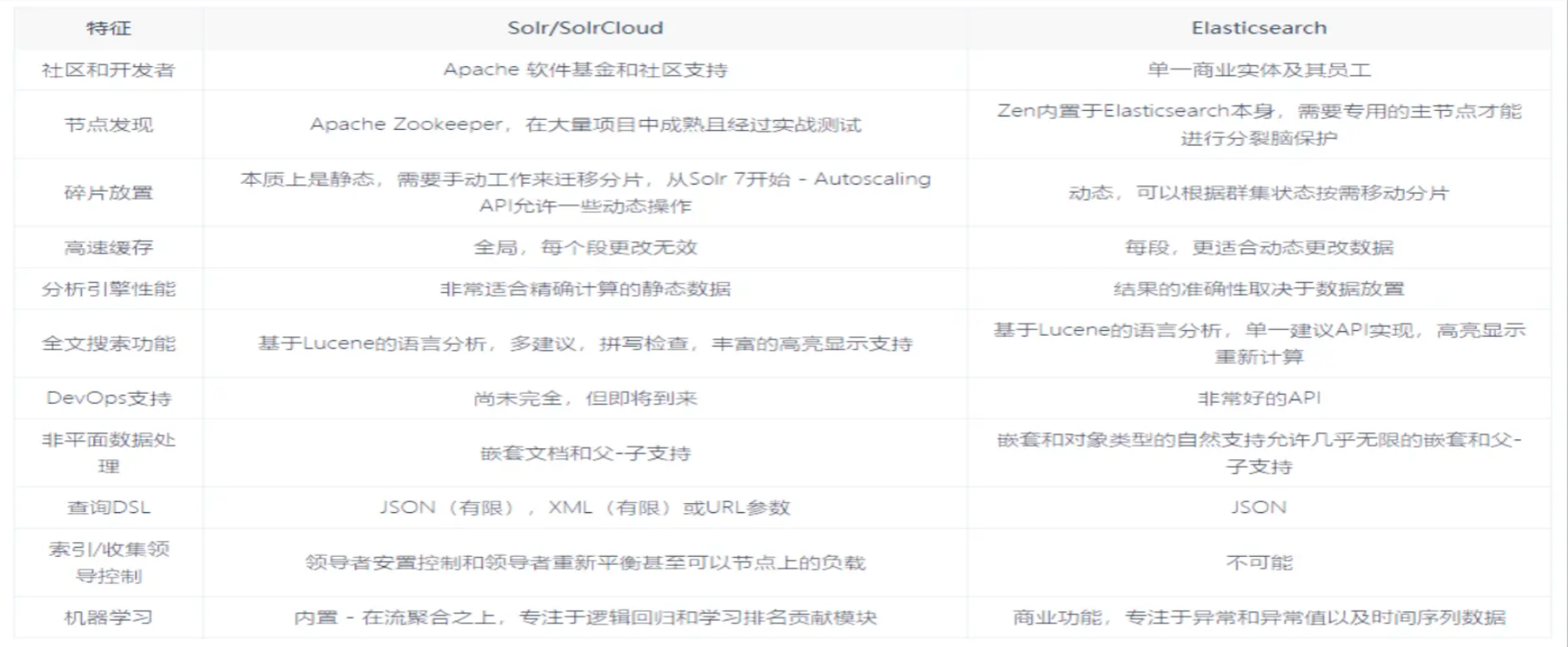
Elasticsearch Or Solr
Elasticsearch 和 Solr 都是开源搜索引擎,那么我们在使用时该如何选择呢?
- Google 搜索趋势结果表明,与 Solr 相比,Elasticsearch 具有很大的吸引力,但这并不意味着 Apache Solr 已经死亡。虽然有些人可能不这么认为,但 Solr 仍然是最受欢迎的搜索引擎之一,拥有强大的社区和开源支持。
- 与 Solr 相比,Elasticsearch 易于安装且非常轻巧。此外,你可以在几分钟内安装并运行Elasticsearch。但是,如果 Elasticsearch 管理不当,这种易于部署和使用可能会成为一个问题。基于 JSON 的配置很简单,但如果要为文件中的每个配置指定注释,那么它不适合您。总的来说,如果你的应用使用的是 JSON,那么 Elasticsearch 是一个更好的选择。否则,请使用 Solr,因为它的 schema.xml 和 solrconfig.xml 都有很好的文档记录。
- Solr 拥有更大,更成熟的用户,开发者和贡献者社区。ES 虽拥有的规模较小但活跃的 用户社区以及不断增长的贡献者社区。
- Solr 贡献者和提交者来自许多不同的组织,而 Elasticsearch 提交者来自单个公司。
- Solr 更成熟,但 ES 增长迅速,更稳定。
- Solr 是一个非常有据可查的产品,具有清晰的示例和 API 用例场景。 Elasticsearch 的文档组织良好,但它缺乏好的示例和清晰的配置说明。
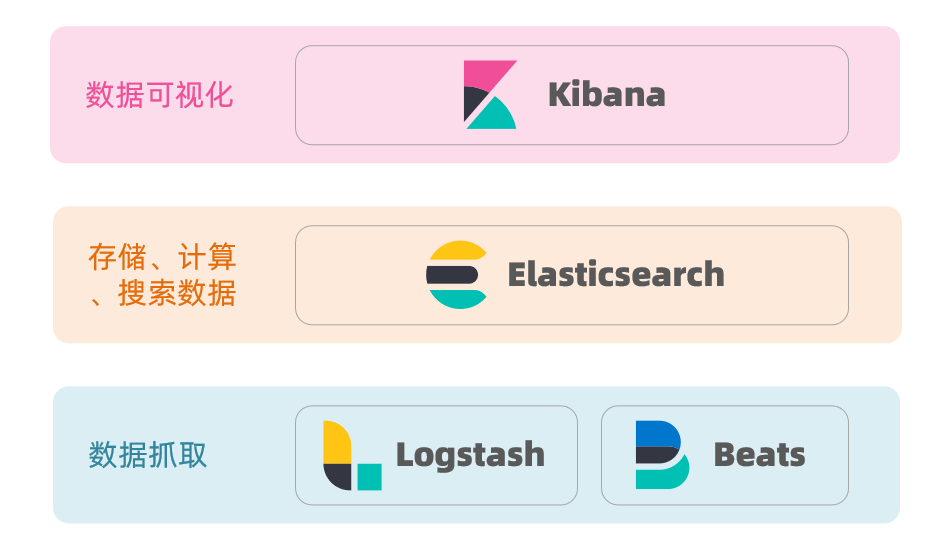
ELK技术栈
elasticsearch结合kibana、Logstash、Beats,也就是elastic stack(ELK)。被广泛应用在日志数据分析、实时监控等领域:
而elasticsearch是elastic stack的核心,负责存储、搜索、分析数据。
为什么不是其他搜索技术?
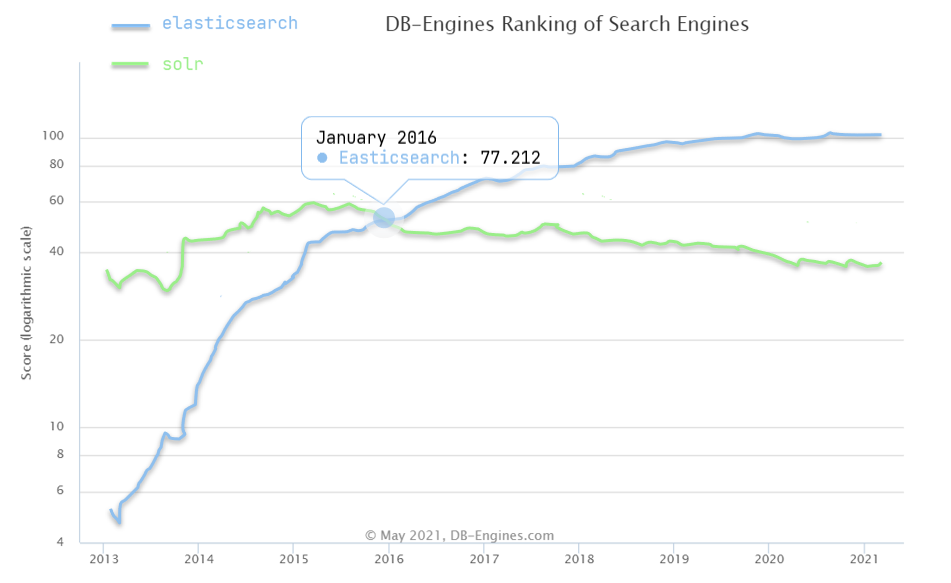
目前比较知名的搜索引擎技术排名:
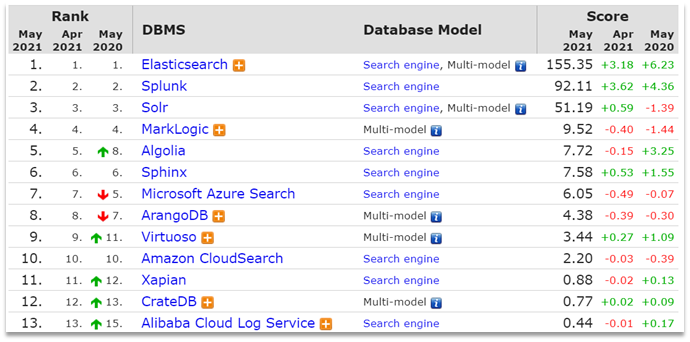
虽然在早期,Apache Solr是最主要的搜索引擎技术,但随着发展elasticsearch已经渐渐超越了Solr,独占鳌头:
Windows上安装ES
下载软件
安装软件
Windows 版的 Elasticsearch 的安装很简单,解压即安装完毕,这里我下载的目前最新版8.12.0,解压后的 Elasticsearch 的目录结构如下
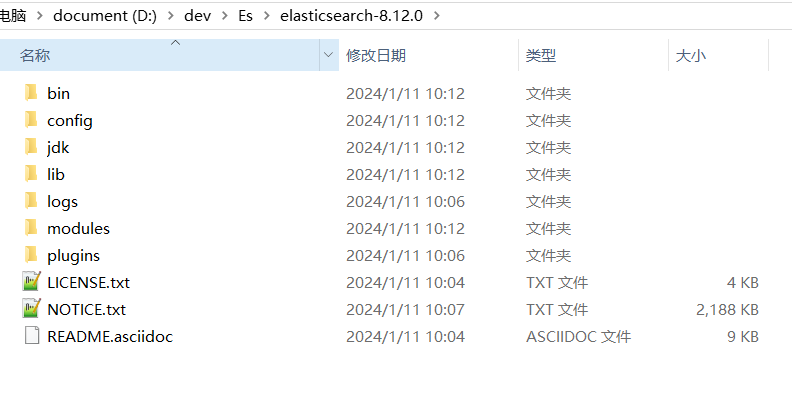
| 目录 | 含义 |
|---|---|
| bin | 可执行脚本 |
| config | 配置目录 |
| jdk | 内置JDK目录 |
| lib | 类库 |
| logs | 日志目录 |
| modules | 模块目录 |
| plugins | 插件目录 |
解压后,我们先来修改一些配置:
配置启动内存,修改配置文件
config/jvm.options1
2
3
4
5
6
7################################################################
## IMPORTANT: JVM heap size
################################################################
## 配置启动内存,默认是4G
-Xms1g
-Xmx1g
################################################################暂时禁止掉再次启动时更新地图的一些数据库操作,修改
config/elasticsearch.yml配置1
2# 添加配置:暂时禁止掉再次启动时更新地图的一些数据库操作
ingest.geoip.downloader.enabled: false进入
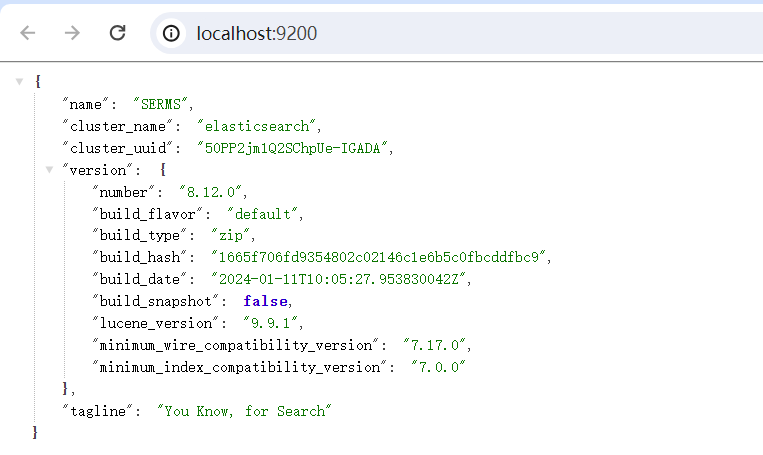
bin文件目录,点击elasticsearch.bat文件启动服务 启动完成后,打开浏览器,输入:http://localhost:9200/

Windows上安装Kibana
Kibana 是一个免费且开放的用户界面,能够让你对 Elasticsearch 数据进行可视化,并 让你在 Elastic Stack 中进行导航。你可以进行各种操作,从跟踪查询负载,到理解请求如 何流经你的整个应用,都能轻松完成。
下载时尽量下载与 ElasicSearch 一致的版本。
下载后进行解压,目录如图:
启动kibana
- 启动
Kibana之前要启动Elasticsearch - 进入
bin目录,双击kibana.bat启动服务 - 启动成功后,复制控制台的地址进行访问http://localhost:5601
- 8.x版本访问时,需要先生成一个
token,我们在ES的bin目录下执行以下命令生成token
1 | es\bin>elasticsearch-create-enrollment-token.bat --scope kibana |
将
token复制到kibana登录页中

修改界面语言
访问界面是英文,可修改成中文,进入根目录下的 config 目录,打开 kibana.yml 文件,在最末尾处加入以下配置,添加完成后,重新启动即可
1 | # 默认端口 |
Docker安装Es
需提前装好Centos系统及Docker
- 因为我们还需要部署kibana容器,因此需要让es和kibana容器互联。这里先创建一个网络:
1 | docker network create es-net |
- 调整机器的vm.max_map_count参数至262144,调整前可以将原文件备份
1 | // 备份文件 |
- 修改虚拟内存区域大小,否则会因为过小而无法启动:
1 | sysctl -w vm.max_map_count=262144 |
- 使用docker命令启动
1 | docker run -d \ |
- 启动时会发现/usr/share/elasticsearch/data目录没有访问权限,只需要修改/mydata/elasticsearch/data目录的权限,再重新启动。
1 | chmod 777 /mydata/elasticsearch/data/ |
部署Kiban
1 | docker run -d \ |
查看日志
1 | docker logs -f kibana |
- 开启防火墙:
1 | firewall-cmd --zone=public --add-port=5601/tcp --permanent firewall-cmd --reload |
安装分词器
前述
为了能够更好地对中文进行搜索和查询,就需要在Elasticsearch中集成好的分词器插件, 而 IK 分词器就是用于对中文提供支持得插件。
集成IK分词器
下载
- IK分词器下载 (opens new window)
- 注意版本需要对应,目前
IK分词器还没有8.3.3版本,所以就先重新下一个8.2.3版本的ES
安装
- 将下载的IK压缩包直接解压到
elasticsearch-8.2.3的plugins目录下,重启ES
使用 IK 分词器
IK 分词器提供了两个分词算法:
▶️ ik_smart: 会做最粗粒度的拆分,适合 Phrase 查询
▶️ Ik_max_word:会将文本做最细粒度的拆分,会穷尽各种可能的组合,适合 Term Query
- 为索引指定默认IK分词器
这样我们在索引中就不用创建每一个字段,可以通过动态字段映射,将String类型的字段映射为text类型,同时分词器指定为ik_max_word
1 | PUT ik_index |
自定义分词效果
- 我们在使用
IK分词器时会发现其实有时候分词的效果也并不是我们所期待的,有时一些特 殊得术语会被拆开,但实际上我们希望不要拆开。 IK插件给我们提供了自定义分词字典,我们可以添加自己想要保留得字了。
自定义分词
- 首先在
elasticsearch-analysis-ik-8.2.3的config目录下新建一个my_self.dic文件,输入自己希望不想被拆开的术语,比如分词词语 - 接下来我们修改配置文件:
config/IKAnalyzer.cfg.xml
1 |
|
热更新 IK 分词使用方法
1 | <!--用户可以在这里配置远程扩展字典 --> |
其中 location 是指一个 url,比如 http://yoursite.com/getCustomDict,该请求只需满足以下两点即可完成分词热更新。
- 1、该 http 请求需要返回两个头部(header),一个是
Last-Modified,一个是ETag,这两者都是字符串类型,只要有一个发生变化,该插件就会去抓取新的分词进而更新词库。 - 2、该 http 请求返回的内容格式是一行一个分词,换行符用
\n即可。
满足上面两点要求就可以实现热更新分词了,不需要重启 ES 实例。
可以将需自动更新的热词放在一个 UTF-8 编码的 .txt 文件里,放在 nginx 或其他简易 http server 下,当 .txt 文件修改时,http server 会在客户端请求该文件时自动返回相应的 Last-Modified 和 ETag。可以另外做一个工具来从业务系统提取相关词汇,并更新这个 .txt 文件。





